
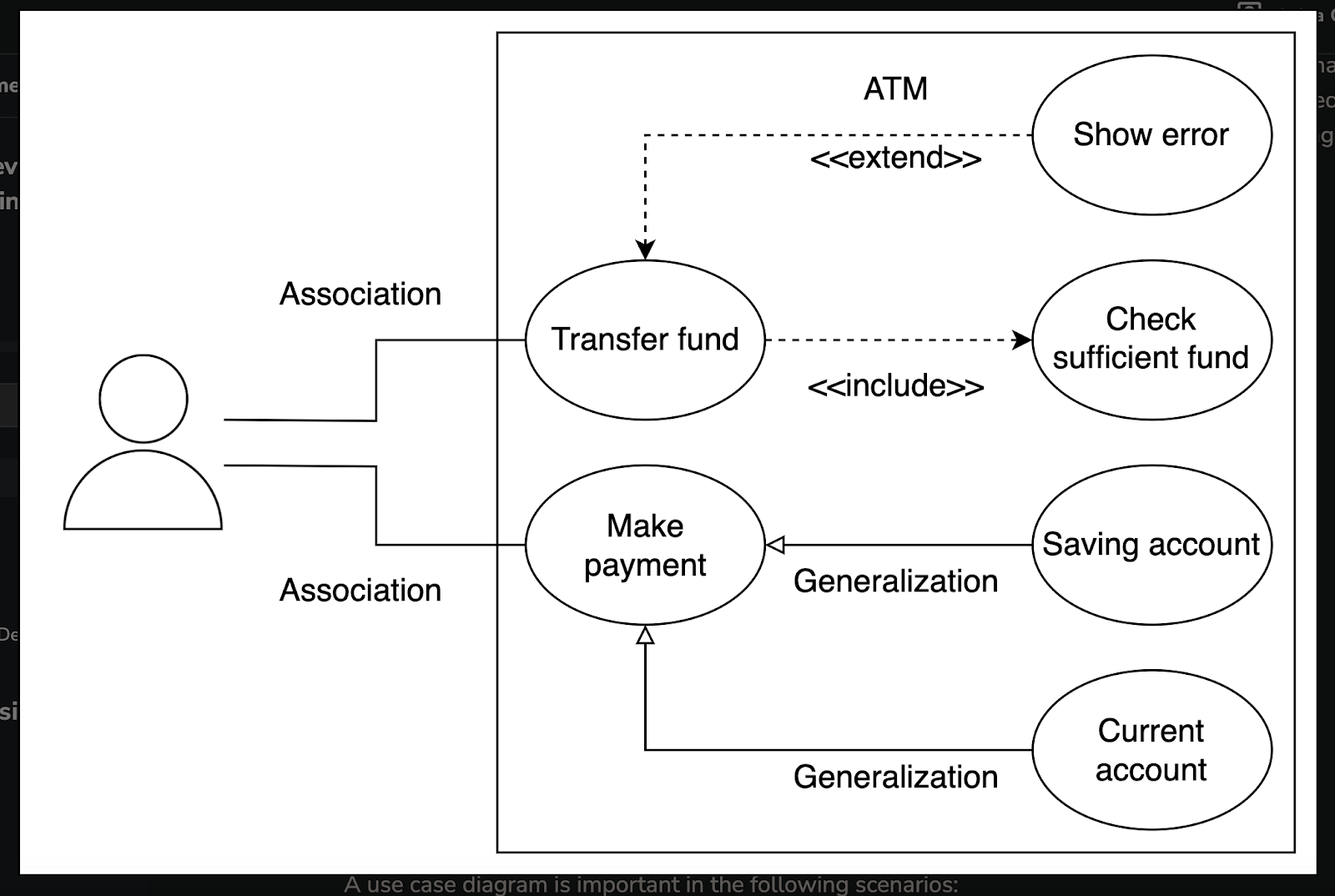
Use Case Diagram
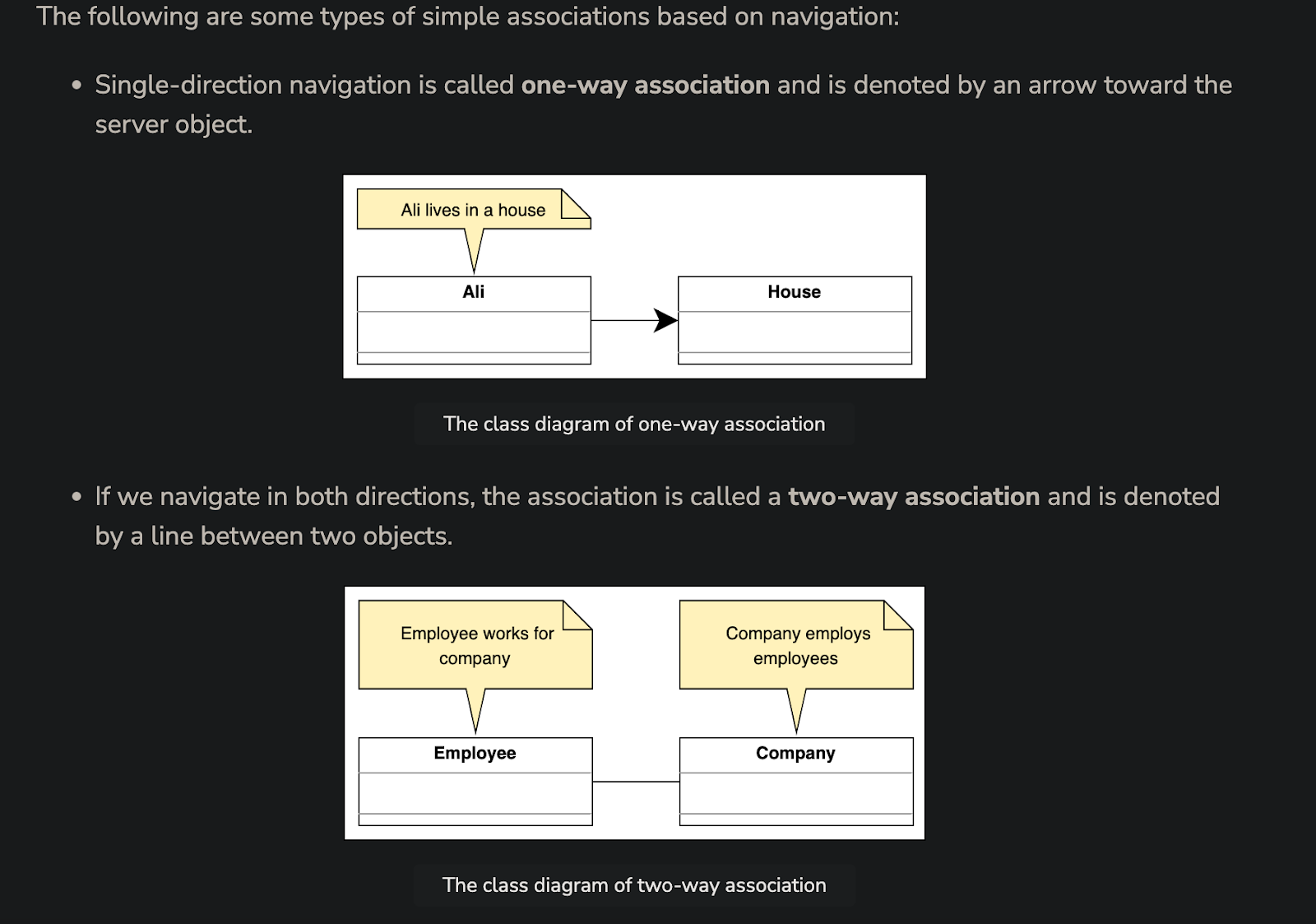
Class Diagram









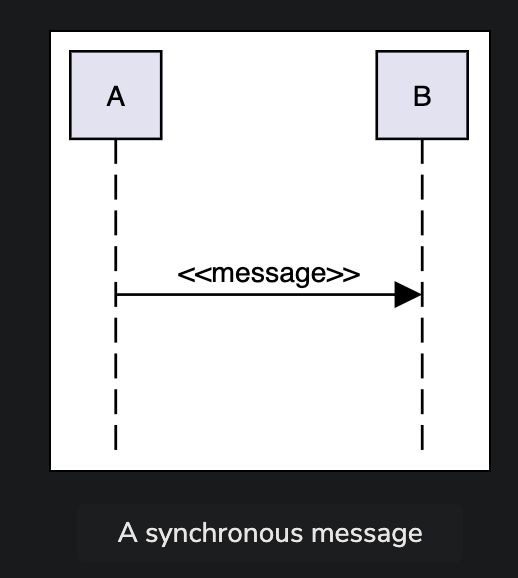
Sequence Diagrams





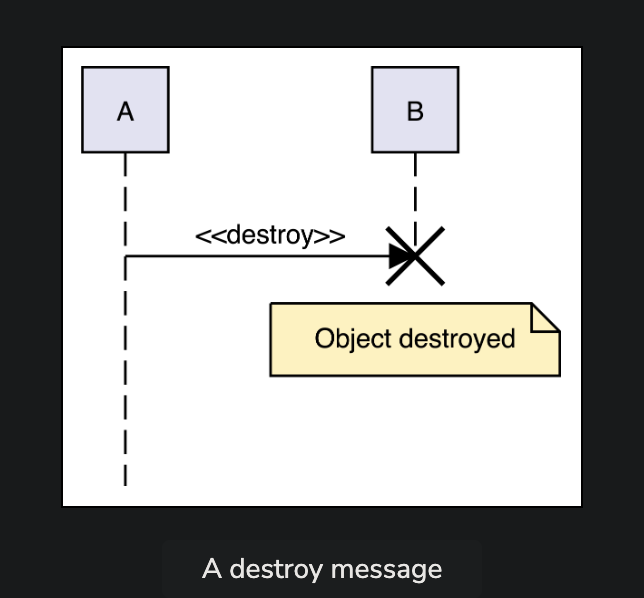

Cash Withdrawl




Activity Diagram








1. The stack data structure can come in handy here in representing this recursive structure of the problem. We can't really process this from the inside out because we don't have an idea about the overall structure. But, the stack can help us process this recursively i.e. from outside to inwards.
2. The capability of finding matching prefix is where the data structure called Trie would shine, comparing the hashset data structure. Not only can Trie tell the membership of a word, but also it can instantly find the words that share a given prefix. As it turns out, the choice of data structure (Trie VS. hashset), which could end with a solution that ranks either the top 5\%5% or the bottom 5\%5%.
Data-intensive applications are pushing the boundaries of what is possible by making use of these technological developments. We call an application data-intensive if data is its primary challenge—the quantity of data, the complexity of data, or the speed at which it is changing—as opposed to compute-intensive, where CPU cycles are the bottleneck
The tools and technologies that help data-intensive applications store and process data have been rapidly adapting to these changes. New types of database systems (“NoSQL”) have been getting lots of attention, but message queues, caches, search indexes, frameworks for batch and stream processing, and related technologies are very important too. Many applications use some combination of these.
Sometimes, when discussing scalable data systems, people make comments along the lines of, “You’re not Google or Amazon. Stop worrying about scale and just use a relational database.” There is truth in that statement: building for scale that you don’t need is wasted effort and may lock you into an inflexible design. In effect, it is a form of premature optimization. However, it’s also important to choose the right tool for the job, and different technologies each have their own strengths and weaknesses. As we shall see, relational databases are important but not the final word on dealing with data.
Ref:https://github.com/ept/ddia-references
This book is arranged into three parts:
In Part I, we discuss the fundamental ideas that underpin the design ofdata-intensive applications. We start in Chapter 1 by discussing what we’re actuallytrying to achieve: reliability, scalability, and maintainability; how we need to think aboutthem; and how we can achieve them. In Chapter 2 we compare several different datamodels and query languages, and see how they are appropriate to different situations. InChapter 3 we talk about storage engines: how databases arrange data on disk so that wecan find it again efficiently. Chapter 4 turns to formats for data encoding (serialization)and evolution of schemas over time.
In Part II, we move from data stored on one machine to data that isdistributed across multiple machines. This is often necessary for scalability, but brings with ita variety of unique challenges. We first discuss replication (Chapter 5),partitioning/sharding (Chapter 6), and transactions (Chapter 7). We thengo into more detail on the problems with distributed systems (Chapter 8) and what itmeans to achieve consistency and consensus in a distributed system (Chapter 9).
In Part III, we discuss systems that derive some datasets from other datasets. Deriveddata often occurs in heterogeneous systems: when there is no one database that can do everythingwell, applications need to integrate several different databases, caches, indexes, and so on. InChapter 10 we start with a batch processing approach to derived data, and we build upon it with stream processing in Chapter 11. Finally, in Chapter 12 we put everythingtogether and discuss approaches for building reliable, scalable, and maintainable applications inthe future.
Question:
Given an array of strings products and a string searchWord. We want to design a system that suggests at most three product names from products after each character of searchWord is typed. Suggested products should have common prefix with the searchWord. If there are more than three products with a common prefix return the three lexicographically minimums products.
Return list of lists of the suggested products after each character of searchWord is typed.
Example 1:
Input: products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse"
Output: [
["mobile","moneypot","monitor"],
["mobile","moneypot","monitor"],
["mouse","mousepad"],
["mouse","mousepad"],
["mouse","mousepad"]
]
Explanation: products sorted lexicographically = ["mobile","moneypot","monitor","mouse","mousepad"]
After typing m and mo all products match and we show user ["mobile","moneypot","monitor"]
After typing mou, mous and mouse the system suggests ["mouse","mousepad"]
Example 2:
Input: products = ["havana"], searchWord = "havana"
Output: [["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
Example 3:
Input: products = ["bags","baggage","banner","box","cloths"], searchWord = "bags"
Output: [["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]
Example 4:
Input: products = ["havana"], searchWord = "tatiana"
Output: [[],[],[],[],[],[],[]]
Solution :
class Solution {
class TrieNode{
TrieNode[] children=new TrieNode[26];
LinkedList<String> suggestions=new LinkedList<>();
boolean isEnd=false;
}
private void insert(String p,TrieNode root){
TrieNode node=root;
for(char ch:p.toCharArray()){
if(node.children[ch-'a']==null){
node.children[ch-'a']=new TrieNode();
}
node=node.children[ch-'a'];
//add the word in the suggestions
node.suggestions.add(p);
Collections.sort(node.suggestions);
if(node.suggestions.size() >3){
node.suggestions.pollLast();
}
}
}
private List<List<String>> search(String searchWord,TrieNode root){
List<List<String>> ans=new ArrayList<>();
TrieNode node=root;
for(char ch:searchWord.toCharArray()){
if(node!=null)
node=node.children[ch-'a'];
ans.add(node== null ? Arrays.asList():node.suggestions);
}
return ans;
}
public List<List<String>> suggestedProducts(String[] products, String searchWord) {
TrieNode root=new TrieNode();
for(String s:products){
insert(s,root);
}
return search(searchWord,root);
}
}
Analysis:
Complexity depends on the sorting, the process of building Trie and the length of searchWord. Sorting cost time O(m * n), due to involving comparing String, which cost time O(m) for each comparison, building Trie cost O(m * n). Therefore,
Time: O(m * n + L), space: O(m * n + L * m) - including return list ans, where m = average length of products, n = products.length, L = searchWord.length().
Leetcode 208. Implement Trie (Prefix Tree)
Implement a trie with insert, search, and startsWith methods.
Example:
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // returns true
trie.search("app"); // returns false
trie.startsWith("app"); // returns true
trie.insert("app");
trie.search("app"); // returns true
Note:
You may assume that all inputs are consist of lowercase letters a-z.
All inputs are guaranteed to be non-empty strings.
Solution :
class Trie {
static class TrieNode{
TrieNode[] children=new TrieNode[26];
boolean isEnd=false;
}
private TrieNode root;
/** Initialize your data structure here. */
public Trie() {
root=new TrieNode();
}
/** Inserts a word into the trie. */
public void insert(String word) {
TrieNode node=root;
for(int i=0;i<word.length();i++){
char ch=word.charAt(i);
if(node.children[ch-'a']==null){
node.children[ch-'a']=new TrieNode();
}
node=node.children[ch-'a'];
}
node.isEnd=true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
TrieNode node=root;
for(int i=0;i<word.length();i++){
char ch=word.charAt(i);
if(node.children[ch-'a']==null)
return false;
node=node.children[ch-'a'];
}
return node.isEnd;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String prefix) {
TrieNode node=root;
for(int i=0;i<prefix.length();i++){
char ch=prefix.charAt(i);
if(node.children[ch-'a']==null)
return false;
node=node.children[ch-'a'];
}
return node != null;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
Trie (pronounce as "Try") is a very popular data structure, usually known as Prefix Tree as well.
Applications:
1. AutoComplete
2. Spell Checker
3. IP Routing (Longest Prefix Matching)
There are several other data structures, like balanced trees and hash tables, which give us the possibility to search for a word in a dataset of strings. Then why do we need trie? Although hash table has O(1) time complexity for looking for a key, it is not efficient in the following operations :
Finding all keys with a common prefix.
Enumerating a dataset of strings in lexicographical order.
Another reason why trie outperforms hash table, is that as hash table increases in size, there are lots of hash collisions and the search time complexity could deteriorate to O(n), where n is the number of keys inserted. Trie could use less space compared to Hash Table when storing many keys with the same prefix. In this case using trie has only O(m) time complexity, where mm is the key length. Searching for a key in a balanced tree costs O(mlogn) time complexity.
Trie node structure
Trie is a rooted tree. Its nodes have the following fields:
Maximum of R links to its children, where each link corresponds to one of R character values from dataset alphabet. In this article we assume that R is 26, the number of lowercase latin letters.
Boolean field which specifies whether the node corresponds to the end of the key, or is just a key prefix.
static class TrieNode{
TrieNode[] children=new TrieNode[26];
boolean isEnd=false;
}
Two of the most common operations in a trie are insertion of a key and search for a key.
Insertion of a key to a trie
We insert a key by searching into the trie. We start from the root and search a link, which corresponds to the first key character. There are two cases :
A link exists. Then we move down the tree following the link to the next child level. The algorithm continues with searching for the next key character.
A link does not exist. Then we create a new node and link it with the parent's link matching the current key character. We repeat this step until we encounter the last character of the key, then we mark the current node as an end node and the algorithm finishes.
/** Inserts a word into the trie. */
public void insert(String word) {
TrieNode node=root;
for(int i=0;i<word.length();i++){
char ch=word.charAt(i);
if(node.children[ch-'a']==null){
node.children[ch-'a']=new TrieNode();
}
node=node.children[ch-'a'];
}
node.isEnd=true;
}
Complexity Analysis
Time complexity : O(m), where m is the key length.
In each iteration of the algorithm, we either examine or create a node in the trie till we reach the end of the key. This takes only mm operations.
Space complexity : O(m).
In the worst case newly inserted key doesn't share a prefix with the the keys already inserted in the trie. We have to add mm new nodes, which takes us O(m)O(m) space.
Search for a key in a trie
Each key is represented in the trie as a path from the root to the internal node or leaf. We start from the root with the first key character. We examine the current node for a link corresponding to the key character. There are two cases :
A link exist. We move to the next node in the path following this link, and proceed searching for the next key character.
A link does not exist. If there are no available key characters and current node is marked as isEnd we return true. Otherwise there are possible two cases in each of them we return false :
There are key characters left, but it is impossible to follow the key path in the trie, and the key is missing.
No key characters left, but current node is not marked as isEnd. Therefore the search key is only a prefix of another key in the trie.

/** Returns if the word is in the trie. */
public boolean search(String word) {
TrieNode node=root;
for(int i=0;i<word.length();i++){
char ch=word.charAt(i);
if(node.children[ch-'a']==null)
return false;
node=node.children[ch-'a'];
}
return node.isEnd;
}
Complexity Analysis
Time complexity : O(m)
Space complexity : O(1)
Reference : https://leetcode.com/problems/implement-trie-prefix-tree/solution/

