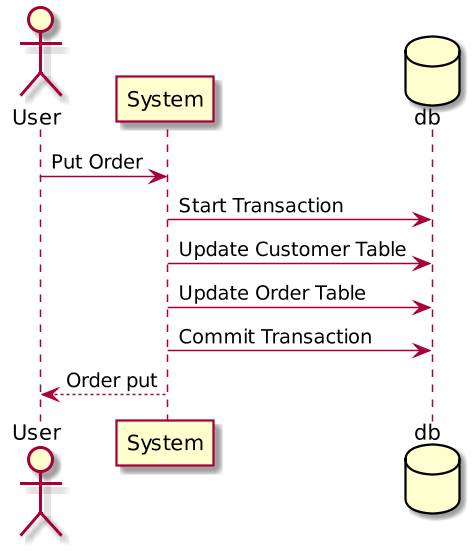
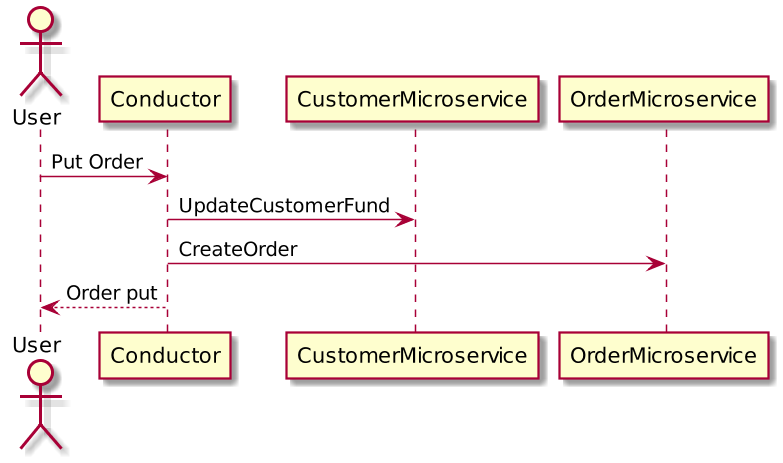
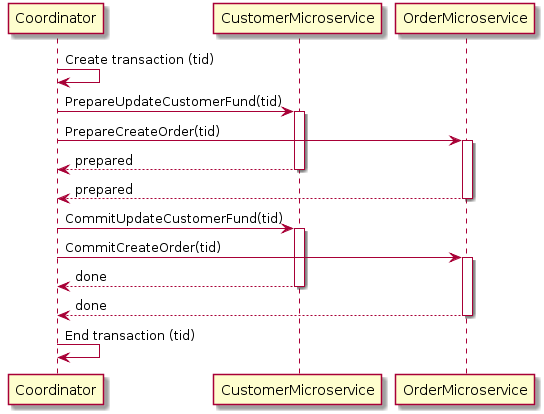
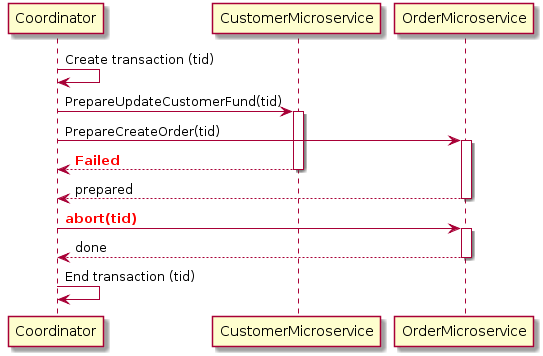
How to stop a Spring Boot based microservices at startup if it can not connect to the Config server during bootstrap?
If you want to halt the service when it is not able to locate the config-server during bootstrap, then you need to configure the following property in microservice’s bootstrap.yml:
spring:
cloud:
config:
fail-fast: true
Using this configuration will make microservice startup fail with an exception when config-server is not reachable during bootstrap.
We can enable a retry mechanism where microservice will retry 6 times before throwing an exception. We just need to add spring-retry and spring-boot-starter-aop to the classpath to enable this feature.
build.gradle:-
...
dependencies {
compile('org.springframework.boot:spring-boot-starter-aop')
compile('org.springframework.retry:spring-retry')
...
}
How big a single microservice should be?
A good, albeit non-specific, rule of thumb is as small as possible but as big as necessary to represent the domain concept they own said by Martin Fowler
Size should not be a determining factor in microservices, instead bounded context principle and single responsibility principle should be used to isolate a business capability into a single microservice boundary.
Microservices are usually small but not all small services are microservices. If any service is not following the Bounded Context Principle, Single Responsibility Principle, etc. then it is not a microservice irrespective of its size. So the size is not the only eligibility criteria for a service to become microservice.
In fact, size of a microservice is largely dependent on the language (Java, Scala, PHP) you choose, as few languages are more verbose than others.
How do microservices communicate with each other?
Microservices are often integrated using a simple protocol like REST over HTTP. Other communication protocols can also be used for integration like AMQP, JMS, Kafka, etc.
The communication protocol can be broadly divided into two categories- synchronous communication and asynchronous communication.
Synchronous Communication
RestTemplate, WebClient, FeignClient can be used for synchronous communication between two microservices. Ideally, we should minimize the number of synchronous calls between microservices because networks are brittle and they introduce latency. Ribbon - a client-side load balancer can be used for better utilization of resource on the top of RestTemplate. Hystrix circuit breaker can be used to handle partial failures gracefully without a cascading effect on the entire ecosystem. Distributed commits should be avoided at any cost, instead, we shall opt for eventual consistency using asynchronous communication.
Asynchronous Communication
In this type of communication, the client does not wait for a response, instead, it just sends the message to the message broker. AMQP (like RabbitMQ) or Kafka can be used for asynchronous communication across microservices to achieve eventual consistency.
What should be preferred communication style in microservices: synchronous or asynchronous?
You must use asynchronous communication while handling HTTP POST/PUT (anything that modifies the data) requests, using some reliable queue mechanism (RabbitMQ, AMQP, etc.)
It's fine to use synchronous communication for Aggregation pattern at API Gateway Level. But this aggregation should not include any business logic other than aggregation. Data values must not be transformed at Aggregator, otherwise, it defeats the purpose of Bounded Context. In Asynchronous communication, events should be published into a Queue. Events contain data about the domain, it should not tell what to do (action) on this data.
If microservice to microservice communication still requires synchronous communication for GET operation, then seriously reconsider the partitioning of your microservices for bounded context, and create some tasks in backlog/technical debt.
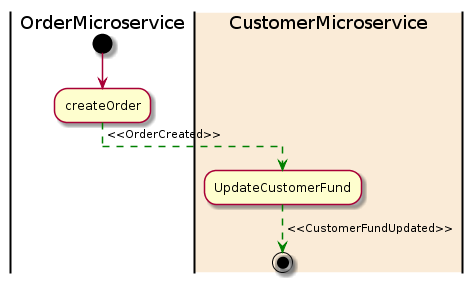
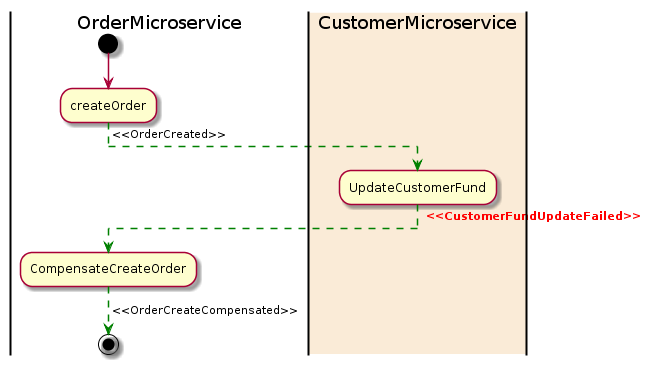
What is the difference between Orchestration and Choreography in microservices context?
In Orchestration, we rely on a central system to control and call other Microservices in a certain fashion to complete a given task. The central system maintains the state of each step and sequence of the overall workflow. In Choreography, each Microservice works like a State Machine and reacts based on the input from other parts. Each service knows how to react to different events from other systems. There is no central command in this case.
Orchestration is a tightly coupled approach and is an anti-pattern in a microservices architecture. Whereas, Choreography’s loose coupling approach should be adopted where-ever possible.
Example
Let’s say we want to develop a microservice that will send product recommendation email in a fictitious e-shop. In order to send Recommendations, we need to have access to user’s order history which lies in a different microservices.
In Orchestration approach, this new microservice for recommendations will make synchronous calls to order service and fetch the relevant data, then based on his past purchases we will calculate the recommendations. Doing this for a million users will become cumbersome and will tightly couple the two microservices.
In Choreography approach, we will use event-based Asynchronous communication where whenever a user makes a purchase, an event will be published by order service. Recommendation service will listen to this event and start building user recommendation. This is a loosely coupled approach and highly scalable. The event, in this case, does not tell about the action, but just the data.
What is API Gateway?
API Gateway is a special class of microservices that meets the need of a single client application (such as android app, web app, angular JS app, iPhone app, etc) and provide it with single entry point to the backend resources (microservices), providing cross-cutting concerns to them such as security, monitoring/metrics & resiliency.
Client Application can access tens or hundreds of microservices concurrently with each request, aggregating the response and transforming them to meet the client application’s needs. Api Gateway can use a client-side load balancer library (Ribbon) to distribute load across instances based on round-robin fashion. It can also do protocol translation i.e. HTTP to AMQP if necessary. It can handle security for protected resources as well.
Features of API Gateway
Spring Cloud DiscoveryClient integration
Request Rate Limiting (available in Spring Boot 2.x)
Path Rewriting
Hystrix Circuit Breaker integration for resiliency
How to achieve zero-downtime during the deployments?
As the name suggests, zero-downtime deployments do not bring outage in a production environment. It is a clever way of deploying your changes to production, where at any given point in time, at least one service will remain available to customers.
Blue-green deployment
One way of achieving this is blue/green deployment. In this approach, two versions of a single microservice are deployed at a time. But only one version is taking real requests. Once the newer version is tested to the required satisfaction level, you can switch from older version to newer version.
You can run a smoke-test suite to verify that the functionality is running correctly in the newly deployed version. Based on the results of smoke-test, newer version can be released to become the live version.
Changes required in client code to handle zero-downtime
Lets say you have two instances of a service running at the same time, and both are registered in Eureka registry. Further, both instances are deployed using two distinct hostnames:
/src/main/resources/application.yml
spring.application.name: ticketBooks-service
---
spring.profiles: blue
eureka.instance.hostname: ticketBooks-service -blue.example.com
---
spring.profiles: green
eureka.instance.hostname: ticketBooks-service -green.example.com
Now the client app that needs to make api calls to books-service may look like below:
@RestController
@SpringBootApplication
@EnableDiscoveryClient
public class ClientApp {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate(); }
@RequestMapping("/hit-some-api")
public Object hitSomeApi() {
return restTemplate().getForObject("https://ticketBooks-service/some-uri", Object.class); }
Now, when ticketBooks-service-green.example.com goes down for upgrade, it gracefully shuts down and delete its entry from Eureka registry. But these changes will not be reflected in the ClientApp until it fetches the registry again (which happens every 30 seconds). So for upto 30 seconds, ClientApp’s @LoadBalanced RestTemplate may send the requests to ticketBooks-service-green.example.com even if its down.
To fix this, we can use Spring Retry support in Ribbon client-side load balancer. To enable Spring Retry, we need to follow the below steps:
Add spring-retry to build.gradle dependencies
compile("org.springframework.boot:spring-boot-starter-aop")
compile("org.springframework.retry:spring-retry")
Now enable spring-retry mechanism in ClientApp using @EnableRetry annotation, as shown below:
@EnableRetry @RestController @SpringBootApplication @EnableDiscoveryClient public class ClientApp {
... }
Once this is done, Ribbon will automatically configure itself to use retry logic and any failed request to ticketBooks-service-green.example.com com will be retried to next available instance (in round-robins fashion) by Ribbon. You can customize this behaviour using the below properties:
/src/main/resources/application.yml
ribbon:
MaxAutoRetries: 5
MaxAutoRetriesNextServer: 5
OkToRetryOnAllOperations: true
OkToRetryOnAllErrors: true
How to achieve zero-downtime deployment(blue/green) when there is a database change?
The deployment scenario becomes complex when there are database changes during the upgrade. There can be two different scenarios: 1. database change is backward compatible (e.g. adding a new table column) 2. database change is not compatible with an older version of the application (e.g. renaming an existing table column)
Backward compatible change: This scenario is easy to implement and can be fully automated using Flyway. We can add the script to create a new column and the script will be executed at the time of deployment. Now during blue/green deployment, two versions of the application (say v1 and v2) will be connected to the same database. We need to make sure that the newly added columns allow null values (btw that’s part of the backward compatible change). If everything goes well, then we can switch off the older version v1, else application v2 can be taken off.
Non-compatible database change: This is a tricky scenario, and may require manual intervention in-case of rollback. Let's say we want to rename first_name column to fname in the database. Instead of directly renaming, we can create a new column fname and copy all existing values of first_name into fname column, keeping the first_name column as it is in the database. We can defer non-null checks on fname to post-deployment success. If the deployment goes successful, we need to migrate data written to first_name by v1 to the new column (fname) manually after bringing down the v1. If the deployment fails for v2, then we need to do the otherwise.
Complexity may be much more in a realistic production app, such discussions are beyond the scope of this book.
How to maintain ACID in microservice architecture?
ACID is an acronym for four primary attributes namely atomicity, consistency, isolation, and durability ensured by the database transaction manager.
Atomicity
In a transaction involving two or more entities, either all of the records are committed or none are.
Consistency
A database transaction must change affected data only in allowed ways following specific rules including constraints/triggers etc.
Isolation
Any transaction in progress (not yet committed) must remain isolated from any other transaction.
Durability
Committed records are saved by a database such that even in case of a failure or database restart, the data is available in its correct state.
In a distributed system involving multiple databases, we have two options to achieve ACID compliance:
One way to achieve ACID compliance is to use a two-phase commit (a.k.a 2PC), which ensures that all involved services must commit to transaction completion or all the transactions are rolled back.
Use eventual consistency, where multiple databases owned by different microservices become eventually consistent using asynchronous messaging using messaging protocol. Eventual consistency is a specific form of weak consistency.
2 Phase Commit should ideally be discouraged in microservices architecture due to its fragile and complex nature. We can achieve some level of ACID compliance in distributed systems through eventual consistency and that should be the right approach to do it.
What is Spring Cloud?
Spring team has an integrated number of battle-tested open-source projects from companies like Pivotal, Netflix into a Spring project known as Spring Cloud. Spring Cloud provides libraries & tools to quickly build some of the common design patterns of a distributed system, including the following:
| Pattern Type | Pattern Name | Spring Cloud Library |
|---|
| Development Pattern | Distributed/versioned configuration management | Spring Cloud Config Server |
| — | Core Microservices Patterns | Spring Boot |
| — | Asynchronous/Distributed Messaging | Spring Cloud Stream (AMQP and Kafka) |
| — | Inter-Service Communication | RestTemplate and Spring Cloud Feign |
| Routing Pattern | Service Registration & Discovery | Spring Cloud Netflix Eureka & Consul |
| Routing Pattern | Service Routing/ API Gateway Pattern | Spring Cloud Netflix Zuul |
| Resiliency Pattern | Client-side load balancing | Spring Cloud Netflix Ribbon |
| — | Circuit Breaker & Fallback Pattern | Spring Cloud Netflix Hystrix |
| — | Bulkhead pattern | Spring Cloud / Spring Cloud Netflix Hystrix |
| Logging Patterns | Log Correlation | Spring Cloud Sleuth |
| — | Microservice Tracing | Spring Cloud Sleuth/Zipkin |
| Security Patterns | Authorization and Authentication | Spring Cloud Security OAuth2 |
| — | Credentials Management | Spring Cloud Security OAuth2/ JWT |
| — | Distributed Sessions | Spring Cloud OAuth2 and Redis |
Spring Cloud makes it really easy to develop, deploy and operate JVM applications for the Cloud.
What are some kind of challenges that distributed systems introduces?
When you are implementing microservices architecture, there are some challenges that you need to deal with every single microservices. Moreover, when you think about the interaction with each other, it can create a lot of challenges. As well as if you pre-plan to overcome some of them and standardize them across all microservices, then it happens that it also becomes easy for developers to maintain services.
Some of the most challenging things are testing, debugging, security, version management, communication ( sync or async ), state maintenance etc. Some of the cross-cutting concerns which should be standardized are monitoring, logging, performance improvement, deployment, security etc.
On what basis should microservices be defined?
It is a very subjective question, but with the best of my knowledge I can say that it should be based on the following criteria.
i) Business functionalities that change together in bounded context
ii) Service should be testable independently.
iii) Changes can be done without affecting clients as well as dependent services.
iv) It should be small enough that can be maintained by 2-5 developers.
v) Reusability of a service
How to tackle service failures when there are dependent services?
In real time, it happens that a particular service is causing a downtime, but the other services are functioning as per mandate. So, under such conditions, the particular service and its dependent services get affected due to the downtime.
In order to solve this issue, there is a concept in the microservices architecture pattern, called the circuit breaker. Any service calling remote service can call a proxy layer which acts as an electric circuit breaker. If the remote service is slow or down for ‘n’ attempts then proxy layer should fail fast and keep checking the remote service for its availability again. As well as the calling services should handle the errors and provide retry logic. Once the remote service resumes then the services starts working again and the circuit becomes complete.
This way, all other functionalities work as expected. Only one or the dependent services get affected.
How can one achieve automation in microservice based architecture?
This is related to the automation for cross-cutting concerns. We can standardize some of the concerns like monitoring strategy, deployment strategy, review and commit strategy, branching and merging strategy, testing strategy, code structure strategies etc.
For standards, we can follow the 12-factor application guidelines. If we follow them, we can definitely achieve great productivity from day one. We can also containerize our application to utilize the latest DevOps themes like dockerization. We can use mesos, marathon or kubernetes for orchestrating docker images. Once we have dockerized source code, we can use CI/CD pipeline to deploy our newly created codebase. Within that, we can add mechanisms to test the applications and make sure we measure the required metrics in order to deploy the code. We can use strategies like blue-green deployment or canary deployment to deploy our code so that we know the impact of code which might go live on all of the servers at the same time. We can do AB testing and make sure that things are not broken when live. In order to reduce a burden on the IT team, we can use AWS / Google cloud to deploy our solutions and keep them on autoscale to make sure that we have enough resources available to serve the traffic we are receiving.
What should one do so that troubleshooting becomes easier in microservice based architecture?
This is a very interesting question. In monolith where HTTP Request waits for a response, the processing happens in memory and it makes sure that the transaction from all such modules work at its best and ensures that everything is done according to expectation. But it becomes challenging in the case of microservices because all services are running independently, their datastores can be independent, REST Apis can be deployed on different endpoints. Each service is doing a bit without knowing the context of other microservices.
In this case, we can use the following measures to make sure we are able to trace the errors easily.
Services should log and aggregators push logs to centralized logging servers. For example, use ELK Stack to analyze.
Unique value per client request(correlation-id) which should be logged in all the microservices so that errors can be traced on a central logging server.
One should have good monitoring in place for each and every microservice in the ecosystem, which can record application metrics and health checks of the services, traffic pattern and service failures.
How should microservices communicate with each other?
It is an important design decision. The communication between services might or might not be necessary. It can happen synchronously or asynchronously. It can happen sequentially or it can happen in parallel. So, once we have decided what should be our communication mechanism, we can decide the technology which suits the best.
Here are some of the examples which you can consider.
A. Communication can be done by using some queuing service like rabbitmq, activemq and kafka. This is called asynchronous communication.
B. Direct API calls can also be made to microservice. With this approach, interservice dependency increases. This is called synchronous communication.
C. Webhooks to push data to connected clients/services.
How would you implement authentication in microservice architecture?
There are mainly two ways to achieve authentication in microservices architecture.
A. Centralized sessions
All the microservices can use a central session store and user authentication can be achieved. This approach works but has many drawbacks as well. Also, the centralized session store should be protected and services should connect securely. The application needs to manage the state of the user, so it is called stateful session.
B. Token-based authentication/authorization
In this approach, unlike the traditional way, information in the form of token is held by the clients and the token is passed along with each request. A server can check the token and verify the validity of the token like expiry, etc. Once the token is validated, the identity of the user can be obtained from the token. However, encryption is required for security reasons. JWT(JSON web token) is the new open standard for this, which is widely used. Mainly used in stateless applications. Or, you can use OAuth based authentication mechanisms as well.
What would be your logging strategy in a microservice architecture?
Logging is a very important aspect of any application. If we have done proper logging in an application, it becomes easy to support other aspects of the application as well. Like in order to debug the issues / in order to understand what business logic might have been executed, it becomes very critical to log important details.
Ideally, you should follow the following practices for logging.
A. In a microservice architecture, each request should have a unique value (correlationid) and this value should be passed to each and every microservice so the correlationid can be logged across the services. Thus the requests can be traced.
B. Logs generated by all the services should be aggregated in a single location so that while searching becomes easier. Generally, people use ELK stack for the same. So that it becomes easy for support persons to debug the issue.
How does docker help in microservice architecture?
Docker helps in many ways for microservices architecture.
A. In a microservice architecture, there can be many different services written in different languages. So a developer might have to setup few services along with its dependency and platform requirements. This becomes difficult with the growing number of services in an ecosystem. However, this becomes very easy if these services run inside a Docker container.
B. Running services inside a container also give a similar setup across all the environments, i.e development, staging and production.
C. Docker also helps in scaling along with container orchestration.
D. Docker helps to upgrade the underlying language very easily. We can save many man-hours.
E. Docker helps to onboard the engineers fast.
F. Docker also helps to reduce the dependencies on IT Teams to set up and manage the different kind of environment required.
How would you manage application configuration in microservice running in a container?
As container based deployment involves a single image per microservice, it is a bad idea to bundle the configuration along with the image.
This approach is not at all scalable because we might have multiple environments and also we might have to take care of geographically distributed deployments where we might have different configurations as well.
Also, when there are application and cron application as part of the same codebase, it might need to take additional care on production as it might have repercussions how the crons are architected.
To solve this, we can put all our configuration in a centralized config service which can be queried by the application for all its configurations at the runtime. Spring cloud is one of the example services which provides this facility.
It also helps to secure the information, as the configuration might have passwords or access to reports or database access controls. Only trusted parties should be allowed to access these details for security reasons.
What is container orchestration and how does it helps in a microservice architecture?
In a production environment, you don’t just deal with the application code/application server. You need to deal with API Gateway, Proxy Servers, SSL terminators, Application Servers, Database Servers, Caching Services, and other dependent services.
As in modern microservice architecture where each microservice runs in a separate container, deploying and managing these containers is very challenging and might be error-prone.
Container orchestration solves this problem by managing the life cycle of a container and allows us to automate the container deployments.
It also helps in scaling the application where it can easily bring up a few containers. Whenever there is a high load on the application and once the load goes down. it can scale down as well by bringing down the containers. It is helpful to adjust cost based on requirements.
Also in some cases, it takes care of internal networking between services so that you need not make any extra effort to do so. It also helps us to replicate or deploy the docker images at runtime without worrying about the resources. If you need more resources, you can configure that in orchestration services and it will be available/deployed on production servers within minutes.
Ex : Kubernetes
Explain the API gateway and why one should use it?
An API Gateway is a service which sits in front of the exposed APIs and acts as an entry point for a group of microservices. Gateway also can hold the minimum logic of routing calls to microservices and also an aggregation of the response.
A. A gateway can also authenticate requests by verifying the identity of a user by routing each and every request to authentication service before routing it to the microservice with authorization details in the token.
B. Gateways are also responsible to load balance the requests.
C. API Gateways are responsible to rate limit a certain type of request to save itself from blocking several kinds of attacks etc.
D. API Gateways can whitelist or blacklist the source IP Addresses or given domains which can initiate the call.
E. API Gateways can also provide plugins to cache certain type of API responses to boost the performance of the application.
How will you ensure data consistency in microservice based architecture?
One should avoid sharing database between microservices, instead APIs should be exposed to perform the change.
If there is any dependency between microservices then the service holding the data should publish messages for any change in the data for which other services can consume and update the local state.
If consistency is required then microservices should not maintain local state and instead can pull the data whenever required from the source of truth by making an API call.
What is event sourcing in microservices architecture?
In the microservices architecture, it is possible that due to service boundaries, a lot of times you need to update one or more entities on the state change of one of the entities. In that case, one needs to publish a message and new event gets created and appended to already executed events. In case of failure, one can replay all events in the same sequence and you will get the desired state as required. You can think of event sourcing as your bank account statement.
You will start your account with initial money. Then all of the credit and debit events happen and the latest state is generated by calculating all of the events one by one. In a case where events are too many, the application can create a periodic snapshot of events so that there isn’t any need to replay all of the events again and again.