How will you implement service discovery in microservices architecture?
Servers come and go in a cloud environment, and new instances of same services can be deployed to cater increasing load of requests. So it becomes absolutely essential to have service registry & discovery that can be queried for finding address (host, port & protocol) of a given server. We may also need to locate servers for the purpose of client-side load balancing (Ribbon) and handling failover gracefully (Hystrix).
Spring Cloud solves this problem by providing a few ready-made solutions for this challenge. There are mainly two options available for the service discovery - Netflix Eureka Server and Consul. Let's discuss both of these briefly:
Netflix Eureka Server
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. The main features of Netflix Eureka are:
It provides service-registry.
zone aware service lookup is possible.
eureka-client (used by microservices) can cache the registry locally for faster lookup. The client also has a built-in load balancer that does basic round-robin load balancing.
Spring Cloud provides two dependencies - eureka-server and eureka-client. Eureka server dependency is only required in eureka server’s build.gradle
build.gradle - Eureka Server
compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-server')
On the other hand, each microservice need to include the eureka-client dependencies to enables
eureka discovery.
build.gradle - Eureka Client (to be included in all microservices)
compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-client')
Eureka server provides a basic dashboard for monitoring various instances and their health in the service registry. The ui is written in freemarker and provided out of the box without any extra configuration. Screenshot for Eureka Server looks like the following.
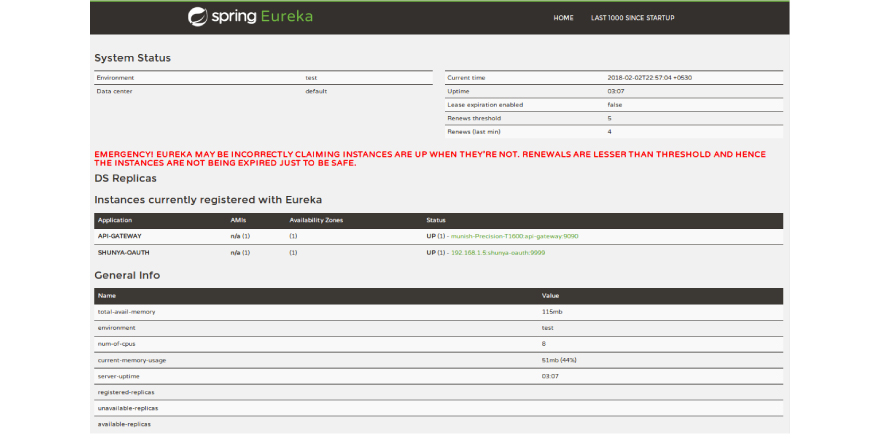
It contains a list of all services that are registered with Eureka Server. Each server has information like zone, host, port, and protocol.
Consul Server
It is a REST-based tool for dynamic service registry. It can be used for registering a new service, locating a service and health checkup of a service.
You have the option to choose any one of the above in your spring cloud-based distributed application. In this book, we will focus more on the Netflix Eureka Server option.
How will you use config-server for your development, stage and production environment?
If you have 3 different environments (develop/stage/production) in your project setup, then you need to create three different config storage projects. So in total, you will have four projects:
config-server
It is the config-server that can be deployed in each environment. It is the Java Code without configuration storage.
config-dev
It is the git storage for your development configuration. All configuration related to each microservices in the development environment will fetch its config from this storage. This project has no Java code, and t is meant to be used with config-server.
config-qa
Same as config-dev but its meant to be used only in qa environment.
Config-prod
Same as config-dev, but meant for production environment.
So depending upon the environment, we will use config-server with either config-dev, config-qa or config-prod.
How does Eureka Server work?
There are two main components in Eureka project: eureka-server and eureka-client.
Eureka Server
The central server (one per zone) that acts as a service registry. All microservices register with this eureka server during app bootstrap.
Eureka Client
Eureka also comes with a Java-based client component, the eureka-client, which makes interactions with the service much easier. The client also has a built-in load balancer that does basic round-robin load balancing. Each microservice in the distributed ecosystem much include this client to communicate and register with eureka-server.
Typical use case for Eureka
There is usually one eureka server cluster per region (US, Asia, Europe, Australia) which knows only about instances in its region. Services register with Eureka and then send heartbeats to renew their leases every 30 seconds. If the service can not renew their lease for a few times, it is taken out of server registry in about 90 seconds. The registration information and the renewals are replicated to all the eureka nodes in the cluster. The clients from any zone can look up the registry information (happens every 30 seconds) to locate their services (which could be in any zone) and make remote calls.
Eureka clients are built to handle the failure of one or more Eureka servers. Since Eureka clients have the registry cache information in them, they can operate reasonably well, even when all of the eureka servers go down.
What is Circuit Breaker Pattern?
Microservices often need to make remote network calls to another microservices running in a different process. Network calls can fail due to many reasons, including-
Brittle nature of the network itself
Remote process is hung or
Too much traffic on the target microservices than it can handle
This can lead to cascading failures in the calling service due to threads being blocked in the hung remote calls. A circuit breaker is a piece of software that is used to solve this problem. The basic idea is very simple - wrap a potentially failing remote call in a circuit breaker object that will monitor for failures/timeouts. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. This mechanism can protect the cascading effects of a single component failure in the system and provide the option to gracefully downgrade the functionality.
A typical use of circuit breaker in microservices architecture looks like the following diagram-

Typical Circuit Breaker Implementation
Here a REST client calls the Recommendation Service which further communicates with Books Service using a circuit breaker call wrapper. As soon as the books-service API calls starts to fail, circuit breaker will trip (open) the circuit and will not make any further call to book-service until the circuit is closed again.
Martin Fowler has beautifully explained this phenomenon in detail on his blog.
Martin Fowler on Circuit Breaker Pattern : https://martinfowler.com/bliki/CircuitBreaker.html
What are Open, Closed and Half-Open states of Circuit Breaker?
Circuit Breaker wraps the original remote calls inside it and if any of these calls fails, the failure is counted. When the service dependency is healthy and no issues are detected, the circuit breaker is in Closed state. All invocations are passed through to the remote service.
If the failure count exceeds a specified threshold within a specified time period, the circuit trips into the Open State. In the Open State, calls always fail immediately without even invoking the actual remote call. The following factors are considered for tripping the circuit to Open State -
An Exception thrown (HTTP 500 error, can not connect)
Call takes longer than the configured timeout (default 1 second)
The internal thread pool (or semaphore depending on configuration) used by hystrix for the command execution rejects the execution due to exhausted resource pool.
After a predetermined period of time (by default 5 seconds), the circuit transitions into a half-open state. In this state, calls are again attempted to the remote dependency. Thereafter the successful calls transition the circuit breaker back into the closed state, while the failed calls return the circuit breaker into the open state.
What are use-cases for Circuit Breaker Pattern and benefits of using Circuit Breaker Pattern?
Synchronous communication over the network that is likely to fail is a potential candidate for circuit breaker.
A circuit breaker is a valuable place for monitoring, any change in the breaker state should be logged so as to enable deep monitoring of microservices. It can easily troubleshoot the root cause of failure.
All places where a degraded functionality can be acceptable to the caller if the actual server is struggling/down.
Benefits:-
The circuit breaker can prevent a single service from failing the entire system by tripping off the circuit to the faulty microservice.
The circuit breaker can help to offload requests from a struggling server by tripping the circuit, thereby giving it a time to recover.
In providing a fallback mechanism where a stale data can be provided if real service is down.
What is the difference between config first bootstrap and discovery first bootstrap in context of Spring Cloud Config client?
Config first bootstrap and discovery first bootstrap are two different approaches for using Spring Cloud Config client in Spring Cloud-powered microservices. Let’s discuss both of them:
Config First Bootstrap
This is the default behavior for any spring boot application where Spring Cloud Config client is on the classpath. When a config client starts up it binds to the Config Server using the bootstrap configuration property and initializes Spring Environment with remote property sources.
Config-first approach
The only configuration that each microservice (except config-server) needs to provide is the following:
File:- /src/main/resources/bootstrap.yml
spring.cloud.config.uri: http://localhost:8888
In config-first approach, even the eureka-server can fetch its own configuration from config-server. Point worth noting down here is that config-server must be the first service to boot up in the entire ecosystem, because each service will fetch its configuration from config-server.
Discovery First Bootstrap
If you are using Spring Cloud Netflix and Eureka Service Discovery then you can have Config Server register with the Discovery Service and let all clients get access to config server via discovery service.
Discovery-first approach
This is not the default configuration in Spring Cloud applications, so we need to manually enable it using the below property in bootstrap.yml
Listing 17. /src/main/resources/bootstrap.yml
spring:
cloud:
config:
discovery:
enabled: true
This property should be provided by all microservices so that they can take advantage of discovery first approach.
The benefit of this approach is that now config-server can change its host/port without other microservices knowing about it since each microservice can get the configuration via eureka service now. The downside of this approach is that an extra network round trip is required to locate the service registration at app startup.
What is Strangulation Pattern in microservices architecture?
Strangulation is used to slowly decommission an older system and migrate the functionality to a newer version of microservices.
Normally one endpoint is Strangled at a time, slowly replacing all of them with the newer implementation. Zuul Proxy (API Gateway) is a useful tool for this because we can use it to handle all traffic from clients of the old endpoints, but redirect only selected requests to the new ones.
Let’s take an example use-case:
/src/main/resources/application.yml
zuul:
routes:
first:
path: /first/**
url: http://first.example.com --1
legacy:
path: /**
url: http://legacy.example.com -- 2
1)Paths in /first/** have been extracted into a new service with an external URL http://first.example.com
2 )legacy app is mapped to handle all request that do not match any other patterns (/first/**).
This configuration is for API Gateway (zuul reverse proxy), and we are strangling selected endpoints /first/ from the legacy app hosted at http://legacy.example.com slowly to newly created microservice with external URL http://first.example.com
What is Hystrix?
Hystrix is Netflix implementation for circuit breaker pattern, that also employs bulkhead design pattern by operating each circuit breaker within its own thread pool. It also collects many useful metrics about the circuit breaker’s internal state, including -
Traffic volume.
Request volume.
Error percentage.
Hosts reporting
Latency percentiles.
Successes, failures, and rejections.
All these metrics can be aggregated using another Netflix OSS project called Turbine. Hystrix dashboard can be used to visualize these aggregated metrics, providing excellent visibility into the overall health of the distributed system.
Hystrix can be used to specify the fallback method for execution in case the actual method call fails. This can be useful for graceful degradation of functionality in case of failure in remote invocation.
Add hystrix library to build.gradle dependencies {
compile('org.springframework.cloud:spring-cloud-starter-hystrix')
1) Enable Circuit Breaker in main application
@EnableCircuitBreaker @RestController @SpringBootApplication
public class ReadingApplication {
... }
2) Using HystrixCommand fallback method execution
@HystrixCommand(fallbackMethod = "reliable")
public String readingList() {
URI uri = URI.create("http://localhost:8090/recommended"); return this.restTemplate.getForObject(uri, String.class);
}
public String reliable() { 2
return "Cached recommended response";
}
Using @HystrixCommand annotation, we specify the fallback method to execute in case of exception.
fallback method should have the same signature (return type) as that of the original method. This method provides a graceful fallback behavior while the circuit is in the open or half-open state.
What are the main features of the Hystrix library?
Hystrix library makes our distributed system resilient (adaptable & quick to recover) to failures. It
provides three main features:
Latency and fault-tolerance
It helps stop cascading failures, provide decent fallbacks and graceful degradation of service functionality to confine failures. It works on the idea of fail-fast and rapid recovery. Two different options namely Thread isolation and Semaphore isolation are available for use to confine failures.
Real-time operations
Using real-time metrics, you can remain alert, make decisions, affect changes and see results.
Concurrency
Parallel execution, concurrent aware request caching and finally automated batching through request collapsing improves the concurrency performance of your application.
More information on Netflix hystrix library:
https://github.com/Netflix/Hystrix/
https://github.com/Netflix/Hystrix/wiki#principles
https://github.com/Netflix/Hystrix/wiki/How-it-Works
What is the difference between using a Circuit Breaker and a naive approach where we try/catch a remote method call and protect for failures?
Let's say we want to handle service to service failure gracefully without using the Circuit Breaker pattern. The naive approach would be to wrap the REST call in a try-catch clause. But Circuit Breaker does a lot more than try-catch can not accomplish -
Circuit Breaker does not even try calls once the failure threshold is reached, doing so reduces the number of network calls. Also, a number of threads consumed in making faulty calls are freed up.
Circuit breaker provides fallback method execution for gracefully degrading the behavior. Try catch approach will not do this out of the box without additional boiler plate code.
Circuit Breaker can be configured to use a limited number of threads for a particular host/API, doing so brings all the benefits of bulkhead design pattern.
So instead of wrapping service to service calls with try/catch clause, we must use the circuit breaker pattern to make our system resilient to failures.
How does Hystrix implement Bulkhead Design Pattern?
The bulkhead implementation in Hystrix limits the number of concurrent calls to a component/service. This way, the number of resources (typically threads) that are waiting for a reply from the component/service is limited.
Let's assume we have a fictitious web e-commerce application as shown in the figure below. The WebFront communicates with 3 different components using remote network calls (REST over HTTP).
Product catalogue Service
Product Reviews Service
Order Service
Now let's say due to some problem in Product Review Service, all requests to this service start to hang (or timeout), eventually causing all request handling threads in WebFront Application to hang on waiting for an answer from Reviews Service. This would make the entire WebFront Application non-responsive. The resulting behavior of the WebFront Application would be same if request volume is high and Reviews Service is taking time to respond to each request.
The Hystrix Solution
Hystrix’s implementation for bulkhead pattern would limit the number of concurrent calls to components and would have saved the application in this case by gracefully degrading the functionality. Assume we have 30 total request handling threads and there is a limit of 10 concurrent calls to Reviews Service. Then at most 10 request handling threads can hang when calling Reviews Service, the other 20 threads can still handle requests and use components Products and Orders Service. This will approach will keep our WebFront responsive even if there is a failure in Reviews Service.
In a microservices architecture, what are smart endpoints and dumb pipes?
Martin Fowler introduced the concept of "smart endpoints & dumb pipes" while describing microservices architecture.
To give context, one of the main characteristic of a based system is to build small utilities and connect them using pipes. For example, a very popular way of finding all java processes in Linux system is Command pipeline in Unix shell ps elf | grep java
Here two commands are separated by a pipe, the pipe’s job is to forward the output of the first command as an input to the second command, nothing more. like a dumb pipe which has no business logic except the routing of data from one utility to another.
In his article Martin Fowler compares Enterprise Service Bus (ESB) to ZeroMQ/RabbitMQ, ESB is a pipe but has a lot of logic inside it while ZeroMQ has no logic except the persistence/routing of messages. ESB is a fat layer that does a lot of things like - security checks, routing, business flow & validations, data transformations, etc. So ESB is a kind of smart pipe that does a lot of things before passing data to next endpoint (service). Smart endpoints & dumb pipes advocate an exactly opposite idea where the communication channel should be stripped of any business-specific logic and should only distribute messages between components. The components (endpoints/services) should do all the data validations, business processing, security checks, etc on those incoming messages.
Microservices team should follow the principles and protocols that worldwide web & Unix is built on.
Servers come and go in a cloud environment, and new instances of same services can be deployed to cater increasing load of requests. So it becomes absolutely essential to have service registry & discovery that can be queried for finding address (host, port & protocol) of a given server. We may also need to locate servers for the purpose of client-side load balancing (Ribbon) and handling failover gracefully (Hystrix).
Spring Cloud solves this problem by providing a few ready-made solutions for this challenge. There are mainly two options available for the service discovery - Netflix Eureka Server and Consul. Let's discuss both of these briefly:
Netflix Eureka Server
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. The main features of Netflix Eureka are:
It provides service-registry.
zone aware service lookup is possible.
eureka-client (used by microservices) can cache the registry locally for faster lookup. The client also has a built-in load balancer that does basic round-robin load balancing.
Spring Cloud provides two dependencies - eureka-server and eureka-client. Eureka server dependency is only required in eureka server’s build.gradle
build.gradle - Eureka Server
compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-server')
On the other hand, each microservice need to include the eureka-client dependencies to enables
eureka discovery.
build.gradle - Eureka Client (to be included in all microservices)
compile('org.springframework.cloud:spring-cloud-starter-netflix-eureka-client')
Eureka server provides a basic dashboard for monitoring various instances and their health in the service registry. The ui is written in freemarker and provided out of the box without any extra configuration. Screenshot for Eureka Server looks like the following.
It contains a list of all services that are registered with Eureka Server. Each server has information like zone, host, port, and protocol.
Consul Server
It is a REST-based tool for dynamic service registry. It can be used for registering a new service, locating a service and health checkup of a service.
You have the option to choose any one of the above in your spring cloud-based distributed application. In this book, we will focus more on the Netflix Eureka Server option.
How will you use config-server for your development, stage and production environment?
If you have 3 different environments (develop/stage/production) in your project setup, then you need to create three different config storage projects. So in total, you will have four projects:
config-server
It is the config-server that can be deployed in each environment. It is the Java Code without configuration storage.
config-dev
It is the git storage for your development configuration. All configuration related to each microservices in the development environment will fetch its config from this storage. This project has no Java code, and t is meant to be used with config-server.
config-qa
Same as config-dev but its meant to be used only in qa environment.
Config-prod
Same as config-dev, but meant for production environment.
So depending upon the environment, we will use config-server with either config-dev, config-qa or config-prod.
How does Eureka Server work?
There are two main components in Eureka project: eureka-server and eureka-client.
Eureka Server
The central server (one per zone) that acts as a service registry. All microservices register with this eureka server during app bootstrap.
Eureka Client
Eureka also comes with a Java-based client component, the eureka-client, which makes interactions with the service much easier. The client also has a built-in load balancer that does basic round-robin load balancing. Each microservice in the distributed ecosystem much include this client to communicate and register with eureka-server.
Typical use case for Eureka
There is usually one eureka server cluster per region (US, Asia, Europe, Australia) which knows only about instances in its region. Services register with Eureka and then send heartbeats to renew their leases every 30 seconds. If the service can not renew their lease for a few times, it is taken out of server registry in about 90 seconds. The registration information and the renewals are replicated to all the eureka nodes in the cluster. The clients from any zone can look up the registry information (happens every 30 seconds) to locate their services (which could be in any zone) and make remote calls.
Eureka clients are built to handle the failure of one or more Eureka servers. Since Eureka clients have the registry cache information in them, they can operate reasonably well, even when all of the eureka servers go down.
What is Circuit Breaker Pattern?
Microservices often need to make remote network calls to another microservices running in a different process. Network calls can fail due to many reasons, including-
Brittle nature of the network itself
Remote process is hung or
Too much traffic on the target microservices than it can handle
This can lead to cascading failures in the calling service due to threads being blocked in the hung remote calls. A circuit breaker is a piece of software that is used to solve this problem. The basic idea is very simple - wrap a potentially failing remote call in a circuit breaker object that will monitor for failures/timeouts. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. This mechanism can protect the cascading effects of a single component failure in the system and provide the option to gracefully downgrade the functionality.
A typical use of circuit breaker in microservices architecture looks like the following diagram-
Typical Circuit Breaker Implementation
Here a REST client calls the Recommendation Service which further communicates with Books Service using a circuit breaker call wrapper. As soon as the books-service API calls starts to fail, circuit breaker will trip (open) the circuit and will not make any further call to book-service until the circuit is closed again.
Martin Fowler has beautifully explained this phenomenon in detail on his blog.
Martin Fowler on Circuit Breaker Pattern : https://martinfowler.com/bliki/CircuitBreaker.html
What are Open, Closed and Half-Open states of Circuit Breaker?
Circuit Breaker wraps the original remote calls inside it and if any of these calls fails, the failure is counted. When the service dependency is healthy and no issues are detected, the circuit breaker is in Closed state. All invocations are passed through to the remote service.
If the failure count exceeds a specified threshold within a specified time period, the circuit trips into the Open State. In the Open State, calls always fail immediately without even invoking the actual remote call. The following factors are considered for tripping the circuit to Open State -
An Exception thrown (HTTP 500 error, can not connect)
Call takes longer than the configured timeout (default 1 second)
The internal thread pool (or semaphore depending on configuration) used by hystrix for the command execution rejects the execution due to exhausted resource pool.
After a predetermined period of time (by default 5 seconds), the circuit transitions into a half-open state. In this state, calls are again attempted to the remote dependency. Thereafter the successful calls transition the circuit breaker back into the closed state, while the failed calls return the circuit breaker into the open state.
What are use-cases for Circuit Breaker Pattern and benefits of using Circuit Breaker Pattern?
Synchronous communication over the network that is likely to fail is a potential candidate for circuit breaker.
A circuit breaker is a valuable place for monitoring, any change in the breaker state should be logged so as to enable deep monitoring of microservices. It can easily troubleshoot the root cause of failure.
All places where a degraded functionality can be acceptable to the caller if the actual server is struggling/down.
Benefits:-
The circuit breaker can prevent a single service from failing the entire system by tripping off the circuit to the faulty microservice.
The circuit breaker can help to offload requests from a struggling server by tripping the circuit, thereby giving it a time to recover.
In providing a fallback mechanism where a stale data can be provided if real service is down.
What is the difference between config first bootstrap and discovery first bootstrap in context of Spring Cloud Config client?
Config first bootstrap and discovery first bootstrap are two different approaches for using Spring Cloud Config client in Spring Cloud-powered microservices. Let’s discuss both of them:
Config First Bootstrap
This is the default behavior for any spring boot application where Spring Cloud Config client is on the classpath. When a config client starts up it binds to the Config Server using the bootstrap configuration property and initializes Spring Environment with remote property sources.
Config-first approach
The only configuration that each microservice (except config-server) needs to provide is the following:
File:- /src/main/resources/bootstrap.yml
spring.cloud.config.uri: http://localhost:8888
In config-first approach, even the eureka-server can fetch its own configuration from config-server. Point worth noting down here is that config-server must be the first service to boot up in the entire ecosystem, because each service will fetch its configuration from config-server.
Discovery First Bootstrap
If you are using Spring Cloud Netflix and Eureka Service Discovery then you can have Config Server register with the Discovery Service and let all clients get access to config server via discovery service.
Discovery-first approach
This is not the default configuration in Spring Cloud applications, so we need to manually enable it using the below property in bootstrap.yml
Listing 17. /src/main/resources/bootstrap.yml
spring:
cloud:
config:
discovery:
enabled: true
This property should be provided by all microservices so that they can take advantage of discovery first approach.
The benefit of this approach is that now config-server can change its host/port without other microservices knowing about it since each microservice can get the configuration via eureka service now. The downside of this approach is that an extra network round trip is required to locate the service registration at app startup.
What is Strangulation Pattern in microservices architecture?
Strangulation is used to slowly decommission an older system and migrate the functionality to a newer version of microservices.
Normally one endpoint is Strangled at a time, slowly replacing all of them with the newer implementation. Zuul Proxy (API Gateway) is a useful tool for this because we can use it to handle all traffic from clients of the old endpoints, but redirect only selected requests to the new ones.
Let’s take an example use-case:
/src/main/resources/application.yml
zuul:
routes:
first:
path: /first/**
url: http://first.example.com --1
legacy:
path: /**
url: http://legacy.example.com -- 2
1)Paths in /first/** have been extracted into a new service with an external URL http://first.example.com
2 )legacy app is mapped to handle all request that do not match any other patterns (/first/**).
This configuration is for API Gateway (zuul reverse proxy), and we are strangling selected endpoints /first/ from the legacy app hosted at http://legacy.example.com slowly to newly created microservice with external URL http://first.example.com
What is Hystrix?
Hystrix is Netflix implementation for circuit breaker pattern, that also employs bulkhead design pattern by operating each circuit breaker within its own thread pool. It also collects many useful metrics about the circuit breaker’s internal state, including -
Traffic volume.
Request volume.
Error percentage.
Hosts reporting
Latency percentiles.
Successes, failures, and rejections.
All these metrics can be aggregated using another Netflix OSS project called Turbine. Hystrix dashboard can be used to visualize these aggregated metrics, providing excellent visibility into the overall health of the distributed system.
Hystrix can be used to specify the fallback method for execution in case the actual method call fails. This can be useful for graceful degradation of functionality in case of failure in remote invocation.
Add hystrix library to build.gradle dependencies {
compile('org.springframework.cloud:spring-cloud-starter-hystrix')
1) Enable Circuit Breaker in main application
@EnableCircuitBreaker @RestController @SpringBootApplication
public class ReadingApplication {
... }
2) Using HystrixCommand fallback method execution
@HystrixCommand(fallbackMethod = "reliable")
public String readingList() {
URI uri = URI.create("http://localhost:8090/recommended"); return this.restTemplate.getForObject(uri, String.class);
}
public String reliable() { 2
return "Cached recommended response";
}
Using @HystrixCommand annotation, we specify the fallback method to execute in case of exception.
fallback method should have the same signature (return type) as that of the original method. This method provides a graceful fallback behavior while the circuit is in the open or half-open state.
What are the main features of the Hystrix library?
Hystrix library makes our distributed system resilient (adaptable & quick to recover) to failures. It
provides three main features:
Latency and fault-tolerance
It helps stop cascading failures, provide decent fallbacks and graceful degradation of service functionality to confine failures. It works on the idea of fail-fast and rapid recovery. Two different options namely Thread isolation and Semaphore isolation are available for use to confine failures.
Real-time operations
Using real-time metrics, you can remain alert, make decisions, affect changes and see results.
Concurrency
Parallel execution, concurrent aware request caching and finally automated batching through request collapsing improves the concurrency performance of your application.
More information on Netflix hystrix library:
https://github.com/Netflix/Hystrix/
https://github.com/Netflix/Hystrix/wiki#principles
https://github.com/Netflix/Hystrix/wiki/How-it-Works
What is the difference between using a Circuit Breaker and a naive approach where we try/catch a remote method call and protect for failures?
Let's say we want to handle service to service failure gracefully without using the Circuit Breaker pattern. The naive approach would be to wrap the REST call in a try-catch clause. But Circuit Breaker does a lot more than try-catch can not accomplish -
Circuit Breaker does not even try calls once the failure threshold is reached, doing so reduces the number of network calls. Also, a number of threads consumed in making faulty calls are freed up.
Circuit breaker provides fallback method execution for gracefully degrading the behavior. Try catch approach will not do this out of the box without additional boiler plate code.
Circuit Breaker can be configured to use a limited number of threads for a particular host/API, doing so brings all the benefits of bulkhead design pattern.
So instead of wrapping service to service calls with try/catch clause, we must use the circuit breaker pattern to make our system resilient to failures.
How does Hystrix implement Bulkhead Design Pattern?
The bulkhead implementation in Hystrix limits the number of concurrent calls to a component/service. This way, the number of resources (typically threads) that are waiting for a reply from the component/service is limited.
Let's assume we have a fictitious web e-commerce application as shown in the figure below. The WebFront communicates with 3 different components using remote network calls (REST over HTTP).
Product catalogue Service
Product Reviews Service
Order Service
Now let's say due to some problem in Product Review Service, all requests to this service start to hang (or timeout), eventually causing all request handling threads in WebFront Application to hang on waiting for an answer from Reviews Service. This would make the entire WebFront Application non-responsive. The resulting behavior of the WebFront Application would be same if request volume is high and Reviews Service is taking time to respond to each request.
The Hystrix Solution
Hystrix’s implementation for bulkhead pattern would limit the number of concurrent calls to components and would have saved the application in this case by gracefully degrading the functionality. Assume we have 30 total request handling threads and there is a limit of 10 concurrent calls to Reviews Service. Then at most 10 request handling threads can hang when calling Reviews Service, the other 20 threads can still handle requests and use components Products and Orders Service. This will approach will keep our WebFront responsive even if there is a failure in Reviews Service.
In a microservices architecture, what are smart endpoints and dumb pipes?
Martin Fowler introduced the concept of "smart endpoints & dumb pipes" while describing microservices architecture.
To give context, one of the main characteristic of a based system is to build small utilities and connect them using pipes. For example, a very popular way of finding all java processes in Linux system is Command pipeline in Unix shell ps elf | grep java
Here two commands are separated by a pipe, the pipe’s job is to forward the output of the first command as an input to the second command, nothing more. like a dumb pipe which has no business logic except the routing of data from one utility to another.
In his article Martin Fowler compares Enterprise Service Bus (ESB) to ZeroMQ/RabbitMQ, ESB is a pipe but has a lot of logic inside it while ZeroMQ has no logic except the persistence/routing of messages. ESB is a fat layer that does a lot of things like - security checks, routing, business flow & validations, data transformations, etc. So ESB is a kind of smart pipe that does a lot of things before passing data to next endpoint (service). Smart endpoints & dumb pipes advocate an exactly opposite idea where the communication channel should be stripped of any business-specific logic and should only distribute messages between components. The components (endpoints/services) should do all the data validations, business processing, security checks, etc on those incoming messages.
Microservices team should follow the principles and protocols that worldwide web & Unix is built on.
No comments:
Post a Comment